The topic I ran Nvidia’s NemoClaw to see if OpenClaw is finally safe, but it still has… is currently the subject of lively discussion — readers and analysts are keeping a close eye on developments.
This is taking place in a dynamic environment: companies’ decisions and competitors’ reactions can quickly change the picture.
A couple of months back, I wrote about why you should stop using OpenClaw. The security vulnerabilities were bad, the architecture was broken by design, and the project’s maintainers seemed more interested in shipping features than fixing the security issues that put users at risk. Since then, OpenClaw has only grown. It has almost 350,000 stars on GitHub, a marketplace full of third-party skills, and a community that treats it like the future of personal AI. Nvidia clearly agreed, because at GTC 2026, the company announced NemoClaw, a security-focused stack designed to wrap OpenClaw in the guardrails it needs.
As someone who isn’t a fan of OpenClaw for those security reasons, I decided to give NemoClaw a try. I’ve been running it over the past few days on the Lenovo ThinkStation PGX, trying to use it as my daily AI assistant. My OpenClaw instance even gave itself a name, Quill, which I thought was charming. And to be fair, there are things NemoClaw gets right. The sandbox model is smart, the policy filtering is aggressive, and Nvidia put thought into the containment architecture.
However, after spending time with it, I still don’t think NemoClaw is the answer. I’ve been dealing with bugs and working around its limitations, and I’ve had to experience all of the downsides of a sandbox model like this while also failing to see much of the actual upside. Can it make a weather request out of the box? No, because it’s blocked. Does this solve prompt injection? Also no, so I’m not convinced that NemoClaw solves the problem it claims to. The device might be secure, sure, but your services are still the bigger issue.
Setting up NemoClaw was not the smooth experience Nvidia’s marketing suggests. The pitch is a single-command deployment through the Nvidia Agent Toolkit, and credit where credit is due, getting it installed on the ThinkStation PGX was straightforward enough. The PGX is a compact little machine powered by Nvidia’s GB10 Grace Blackwell Superchip with 128GB of unified memory, and it handles local inference without issue. I’ve been running all kinds of models on it without issue, but actually using NemoClaw day to day is frustrating.
My first plan was to run Nemotron 3 Super 120B through llama.cpp, which is my usual go-to for local inference. The model itself is impressive, a hybrid Mamba-Transformer with a Mixture-of-Experts architecture that only activates 12 billion parameters at a time out of the full 120 billion. That MoE design makes it surprisingly fast for its size, and regular responses come back pretty quickly.
Unfortunately, NemoClaw couldn’t work with this model when I used llama.cpp. In my case, the problem was specifically caused by tool calling, as llama.cpp’s grammar-based approach to constraining output couldn’t reliably parse the structured tool call format that NemoClaw expects. The model would generate valid completions on its own, but the moment NemoClaw tried to route a tool call through its sandbox, the grammar parsing seemed to fall apart. I ended up switching to Ollama, which handled the tool calling format without issues. Nvidia’s own instructions say to use Ollama, but it’s frustrating that I can’t use llama.cpp when that’s how nearly all of my other models are hosted.
Then there’s the permissions bug. I hit a documented problem almost immediately, where the OpenClaw gateway can’t access its own approval configuration file because the sandbox directory is owned by root instead of the sandbox user. The workaround is a manual chown command inside the container, which works but feels absurd for a security product. The underlying permission model feels almost suffocatingly locked down, given that we’re at a point where it locks itself out. There’s a pull request open to fix it, but it hasn’t been merged.
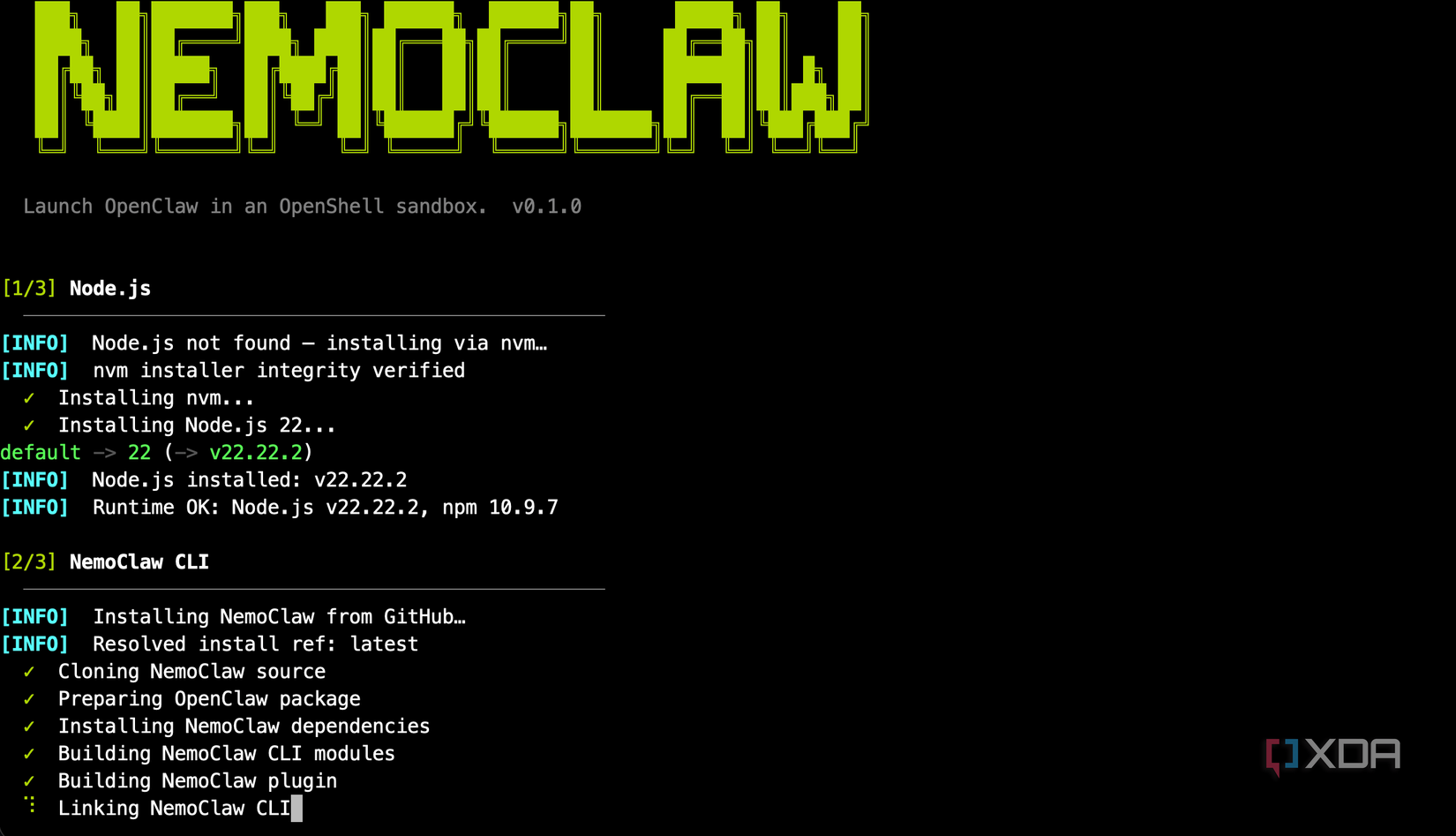
The Telegram bridge, which is how I’ve been interacting with Quill most of the time, required an Nvidia API key despite the fact that NemoClaw supports local inference backends like Ollama. In the above screenshot, I set the key value to be empty, then tried to start it. It failed without the key. Then I uncommented the variable from my .bashrc where I have my Nvidia API key exported, sourced it, and then it would start. This means that Telegram messages route through Nvidia’s architecture, and it’s not documented particularly well, either. Plus, it means your “local” assistant is still phoning the cloud in a way that might matter depending on your threat model.
To make matters worse, after leaving NemoClaw running overnight, I came back to find the OpenClaw dashboard completely unreachable, just`ERR_CONNECTION_RESET every time I tried to load it in a browser. Quill was still responding on Telegram, so the service itself was up, but the dashboard had lost connectivity. I wasn’t able to diagnose the cause, but if I were to guess, I would suspect the proxy that OpenShell uses for network isolation had a role to play, given that I couldn’t curl the OpenClaw dashboard from the PGX host, either. Unfortunately, this is the system that forms a large part of the overall security architecture, but when your security layer breaks your own access to the management interface, that’s a problem. Re-running the NemoClaw onboard script got me back in, at least.
To NemoClaw’s credit, the containment model is well thought out. OpenShell runs a deny-by-default network policy, which means the sandbox can only reach endpoints that are explicitly whitelisted. Every outbound request that doesn’t match an approved destination gets intercepted, logged, and blocked. That’s a big step up from running OpenClaw on a bare system where the agent inherits whatever network access the host machine has.
I saw this firsthand when I asked Quill to check the weather; a simple request, I thought. Instead, OpenShell blocked it. The sandbox logs showed the request being denied because wttr.in wasn’t in any of the approved policies like “claude_code”, “clawhub”, or “telegram”. Quill tried Ireland first, then Dublin, and both got blocked. The system did exactly what it was designed to do: it prevented the agent from reaching an unapproved endpoint.
That’s the right behavior from a security perspective. The problem is that it makes the assistant almost useless out of the box. You can add endpoints to the allow list through the OpenShell TUI or by editing the policy YAML, but the default “suggested presets” are even more restrictive than this, as the only preapplied presets were for pypi and npm. NemoClaw’s privacy router also decides whether inference stays local or routes to cloud models based on policy rather than agent preference, which is the right call from a security standpoint but adds yet more friction in practice.
The filesystem and process containment is solid too. OpenShell uses kernel-level isolation to prevent agents from reading arbitrary paths on the host or persisting changes across runs. The critical design decision here is that the policy enforcement happens outside the agent process, means the agent can’t override its own containment by manipulating prompts from within. That’s good design, and it’s yet another point that Nvidia got right. If you’re going to run OpenClaw, running it inside NemoClaw is much better than running it bare.
But “better than bare” is a low bar when the thing you’re containing is inherently dangerous.
This is what keeps bugging me about the whole NemoClaw pitch: OpenClaw is useful because it connects to your services. Email, messaging, calendars, cloud storage, code repositories, these are the integrations that make an AI assistant actually assistive. And every single one of those connections is a way in for prompt injection, credential theft, or worse.
NemoClaw’s sandbox can prevent the agent from dialing out to arbitrary endpoints, stop it from reading your host filesystem, and log every tool call and network request for audit. What it cannot do is prevent a malicious instruction embedded in a webpage, an email, or a Telegram message from influencing the model’s behavior. If someone sends you an email that contains a carefully crafted prompt injection, and your OpenClaw agent processes that email, the sandbox won’t help. The agent isn’t escaping containment, it’s operating within its approved boundaries while doing something you didn’t authorize.
This isn’t theoretical, either. for example, PromptArmor demonstrated that the link preview feature in messaging apps like Telegram and Discord can be turned into a data exfiltration pathway through indirect prompt injection. The attacker tricks the agent into generating a URL that automatically transmits confidential data to an attacker-controlled domain. The agent isn’t breaking out of the sandbox, it’s using the approved Telegram connection, which it needs to function, to leak your data. You can (and should) set approved IDs for messaging your bot, but that’s not the point. There are creative ways around these restrictions, and the more services you link to, the more risk there is.
OWASP still treats prompt injection as a primary risk for agentic systems, placing it at the number one spot on its top 10 list for LLMs, and for good reason. As an example, 1Password’s SCAM benchmark found that AI agents can recognize phishing or risky content and still proceed to execute dangerous actions anyway. In those instances, a model that “knows” something looks suspicious but follows the instruction regardless is not made safe by a network policy.
Then there’s the identity problem. NemoClaw can’t rewrite your Identity and Access Management (IAM) model. If you give your OpenClaw agent broad credentials, which you kind of have to for it to be useful, then anyone who compromises the agent through prompt injection inherits that same access. Microsoft’s own agentic security framework treats identity governance as a core requirement for autonomous AI, and NemoClaw leaves it entirely to the user to figure out.
And the malicious skills problem hasn’t gone away either. Multiple audits have found a huge number of dangerous skills on the ClawHub repository. NemoClaw’s sandbox helps contain the damage from a malicious skill, sure, but an isolated instance of OpenClaw is not a substitute for active security involving allowlists and static analysis. If you install a skill that exfiltrates your session tokens through an approved API endpoint, the sandbox will allow it without even questioning it.
The issue I keep coming back to is that OpenClaw merges the control plane with the data plane. The same channel that carries instructions to the agent, natural language prompts, also carries the data the agent processes, which includes untrusted content from emails, webpages, and messages. Decades of systems design have taught us to keep these planes separate, and OpenClaw’s architecture deliberately collapses them because that’s what makes conversational AI agents feel seamless.
NemoClaw addresses this at the network level by controlling what the agent can reach, but it doesn’t address it at the semantic level. The model still processes untrusted input alongside trusted instructions, and it still makes judgment calls about what to do with that input. OpenShell can’t inspect the meaning of a request, only the destination. A tool call to an approved endpoint that happens to be exfiltrating data looks identical to a legitimate request from the sandbox’s perspective.
OpenClaw’s own documentation describes its security model as “personal assistant,” meaning one trusted operator with potentially many agents, not a “shared multi-tenant bus.” Running one gateway for multiple mutually untrusted users is explicitly not a recommended setup. NemoClaw’s containment doesn’t change that. It just makes the single-operator case slightly less catastrophic when things go wrong.
I’m not saying NemoClaw is useless, and in fact, it’s a real step forward for anyone who insists on running OpenClaw. The deny-by-default networking, the out-of-process policy enforcement, and the filesystem isolation are all things that go a long way towards solving part of the OpenClaw security problem, and running it inside NemoClaw is measurably safer than running it bare. But “safer” and “safe” are different words, and Nvidia’s marketing doesn’t really make that distinction clear, especially when the company’s own announcement really buries the fact that NemoClaw currently exists as an early preview, rather than a complete system.
Quill is still running on my ThinkStation PGX. It responds quickly, handles complex queries well, and the MoE architecture means Nemotron 3 Super 120B runs faster than you’d expect for a model of that size. When I can actually reach the dashboard, it’s a polished experience. But every time I think about what’s happening underneath, about the Telegram messages being processed, the tool calls being made, the services being accessed on my behalf, I keep circling back to the same concern I had months ago. The device isn’t the problem. It never was. The problem is what happens when you give an AI agent the keys to your digital life and hope that a sandbox is enough to keep it honest.
The Lenovo Thinkstation PGX is a mini PC powered by Nvidia’s GB10 Grace Blackwell Superchip. It has 128 GB of VRAM for local AI workloads, and can be used for quantization, fine-tuning and all things CUDA.